

Bessere Performance bei Datenabfragen durch Redis und Spring Cache
Hat eure Anwendung Probleme mit langsamen Zugriffen auf Datenbanken oder andere Content liefernde Medien? Dann kann ein Cache mit Hilfe der schnellen In-Memory NoSQL Datenbank Redis helfen. Verwendet Spring Data und Spring Cache, dann müsst ihr nicht im Detail verstehen wie Redis funktioniert.
Überblick Cache und Redis
Cache
Ein Cache wird immer zwischen eine Anwendung oder einen Client und ein Hintergrundmedium (z.B. eine Datenbank oder ein Laufwerk) geschaltet. Vereinfacht gesagt, speichert der Cache die Daten, die vom Hintergrundmedium abgefragt wurden, so dass beim nächsten Zugriff auf dieselben Daten, die Auslieferung aus dem Cache erfolgt. Ein Cache ist für die besonders schnelle Auslieferung seiner Daten optimiert. Dadurch bekommt die Anwendung oder der Client schnellere Antworten vom Cache im Vergleich zu den langsamen Antworten des Hintergrundmediums.
Das folgende Schaubild zeigt wie eine Spring Anwendung eine MongoDB als Hintergrundmedium verwendet und die abgefragten Daten in einem Redis Cache speichert. Diese Daten werden in späteren Anfragen direkt und somit schneller aus dem Cache geliefert, so dass die MongoDB für diese Anfragen nicht mehr benutzt wird.
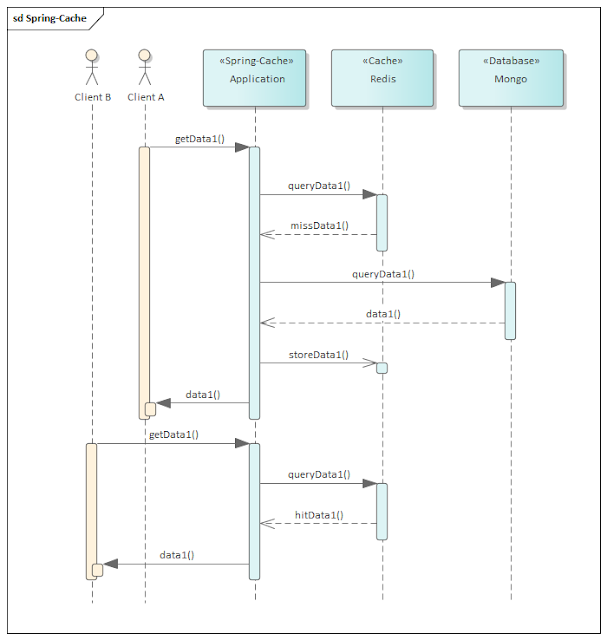 |
| Beide Clients fragen denselben Datensatz ab |
Es gibt verschiedene Cache-Strategien, die das Zusammenspiel zwischen Anwendung, Cache und Hintergrundmedium definieren und optimieren. Schaut euch diese weiterführende Theorie bei Interesse hier an: https://de.wikipedia.org/wiki/Cache-Algorithmus
Video zum Blog-Artikel
Redis
Redis ist eine NoSQL Datenbank, welche die Datenhaltung im Arbeitsspeicher macht und somit sehr schnelle Antwortzeiten ermöglicht. Redis ist deshalb eine beliebte Opensource Cache Lösung, kann aber auch für andere Szenarien eingesetzt werden, siehe dazu https://redis.com/why-redis/.
Die Besonderheiten von Redis und wie es genau funktioniert, muss uns hier nicht interessieren, da Spring für uns die Interaktion mit Redis managt. Deshalb werde ich hier auch nicht weiter auf Redis eingehen.
Spring Data und Spring Cache
Spring Boot Dependencies für Maven oder Gradle
Spring Boot hilft uns, wie so häufig, mit dem Konfigurieren unseres Projektes, so dass wir Redis als Cache in unserer Anwendung verwenden können. Wenn ihr ein Spring Boot Projekt habt oder erstellt, benötigt ihr diese beiden Dependencies für Redis und den Cache - hier ein Ausschnitt aus der Gradle Konfiguration:
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-webflux'
implementation 'org.springframework.boot:spring-boot-starter-data-mongodb-reactive'
implementation 'org.springframework.boot:spring-boot-starter-cache'
implementation 'org.springframework.boot:spring-boot-starter-data-redis'
...
}
Ihr benötigt eigentlich nur die beiden fett markierten Bibliotheken:
- spring-boot-starter-cache für die Caching Logik von Spring.
- spring-boot-starter-data-redis für die Interaktion mit Redis gemanagt durch Spring Data.
- Die beiden anderen Bibliotheken habe ich in diesem Blog-Artikel erklärt:
spring-data-reactive.html
Der Code zu diesem Blog-Artikel wurde in den Code des anderen Artikels integriert, weil ich dort schon die MongoDB im Einsatz hatte.
Redis Verbindung konfigurieren
Die Connection zu Redis kann mittels den Spring Boot Properties in der application.properties Datei konfiguriert werden. Hier ist eine Beispiel-Konfiguration für eine Redis Datenbank, die in einem lokalen Docker Container läuft:
spring.redis.host=localhost
spring.redis.port=6379
spring.redis.password=geheim
# Festlegen was als Cache fungiert,
# wird im Default automatisch erkannt.
spring.cache.type=redis
# Lese-Timeout für den Zugriff auf Redis in Millisekunden.
spring.redis.timeout=5000
Exkurs: Redis im Docker Container starten
Wie man Docker-Container startet, habe ich in diesem Artikel anhand einer MongoDB ausführlich erklärt: keine-ahnung-von-mongodb-dann-nimm.html.
Um mich nicht zu wiederholen zeige ich euch hier eine Möglichkeit zum Starten eines Redis Servers im Docker Container:
Um mich nicht zu wiederholen zeige ich euch hier eine Möglichkeit zum Starten eines Redis Servers im Docker Container:
docker run -d -p 6379:6379 redis redis-server --requirepass "geheim"
Das Passwort (hier "geheim") muss auch in den Spring Properties hinterlegt werden. Zum Testen könnte man es aber auch einfach weglassen (--requirepass).
Für dieses Tutorial benötigt ihr zusätzlich eine MongoDB, die ihr wie folgt als Docker Container starten könnt:
docker run -d -p 27017:27017 --name mongodb mongo
docker run -d -p 27017:27017 --name mongodb mongo
RedisCacheConfiguration Bean
Das Konfigurieren und Aktivieren des Spring Caches funktioniert mittels Spring @Configuration Bean und @EnableCaching Annotation für unsere Spring Boot Anwendung:
@Configuration
@EnableCaching
public class EmployeeCacheConfiguration {
@Bean
public RedisCacheConfiguration cacheConfiguration() {
return RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofMinutes(1))
.serializeValuesWith(SerializationPair.fromSerializer(
new GenericJackson2JsonRedisSerializer()));
}
}
- Die RedisCacheConfiguration Bean richtet dabei unser Caching in Redis ein.
- Die hier gezeigte RedisCacheConfiguration Bean basiert auf den Default-Einstellungen (defaultCacheConfig) wurde dann aber angepasst. Mit serializeValuesWith lege ich den Serialisierer fest, der die Daten im gewünschten Format JSON in den Cache schreibt. Hier könnt ihr bei Bedarf eingreifen und einen eigenen ObjectMapper für komplexe JSON-Strukturen übergeben.
- Die "Time-To-Life" von Objekten im Cache wird mit entryTtl definiert - hier eine Minute. "Time-To-Life" bedeutet, dass ein Objekt nach einer Minute aus dem Cache entfernt wird und dann wieder neu von der Datenbank oder einer anderen Quelle gelesen werden muss. Diese kurze TTL habe ich hier für Demonstrationszwecke gewählt.
Caching per Annotation
Nun können wir auf Klassen- oder Methoden-Ebene das Caching aktivieren. Dazu verwenden wir, wie in Spring üblich, eine Annotation: @Cacheable.
@Service
@Cacheable(cacheNames = EmployeeCacheService.EMPLOYEE_CACHE)
public class EmployeeCacheService {
public static final String EMPLOYEE_CACHE = "employeeCache";
@Autowired private ReactiveEmployeeRepository mongoRepo;
public List<EmployeeDAO> getAllEmployees() {
return mongoRepo.findAll().toStream().collect(Collectors.toList());
}
}
- Der EmployeeCacheService ist eine ganz normale Bean, die Daten aus der MongoDB liest, indem sie auf eine von Spring Data bereitgestellte Instanz von ReactiveEmployeeRepository zugreift. Alternativ könnten hier auch komplexe längere Berechnungen stattfinden oder langsame Backends aufgerufen werden, also Szenarien in denen sich Caching lohnt.
- Die Nutzung des Caches wird durch die Annotation @Cacheable aktiviert - mehr müssen wir nicht tun! Ich habe hier noch einen Namen für den Cache festgelegt, so dass ich ihn über den CacheManager holen und bearbeiten kann. Das mache ich z.B. in meinem JUnit Test, um den Redis Cache vor jedem Test zu leeren:
@Autowired private CacheManager cacheManager;
@BeforeEach
void setup() {
cacheManager.getCache(EmployeeCacheService.EMPLOYEE_CACHE).clear();
}
Caching Testen
Das Caching unserer Anwendung können wir mit JUnit testen, indem wir überprüfen, ob die Methode mit aktiviertem Cache (hier getAllEmployees) bei mehreren Aufrufen nur einmal mit der Datenbank (hier ReactiveEmployeeRepository) interagiert.
@SpringBootTest(classes = {EmployeeCacheService.class,
EmployeeCacheConfiguration.class})
@EnableCaching
@ImportAutoConfiguration(classes = {CacheAutoConfiguration.class,
RedisAutoConfiguration.class })
class EmployeeCacheServiceTest {
@MockBean private ReactiveEmployeeRepository dbMock;
@Autowired private EmployeeCacheService cachedService;
@Autowired private CacheManager cacheManager;
@BeforeEach
void setup() {
when(dbMock.findAll()).thenReturn(Flux.fromArray(new EmployeeDAO[] {
(new EmployeeDAO("1", "1", "Hansi", 18))}));
cacheManager.getCache(EmployeeCacheService.EMPLOYEE_CACHE).clear();
}
@Test
void getAllEmployees() {
cachedService.getAllEmployees();
cachedService.getAllEmployees();
verify(dbMock, times(1)).findAll();
}
}
- Die Überprüfung, dass der Cache bei 2 Methodenaufrufen einmal benutzt wurde, mache ich, indem ich verifiziere, dass der Datenbank-Mock dbMock nur einmal aufgerufen wurde. Wie das dazu verwendete Framework Mockito funktioniert, ist hier erklärt: spring-and-mockito.html
- Die beiden Annotationen @EnableCaching und @ImportAutoConfiguration optimieren die Ausführungszeit des Tests. Sie sorgen dafür, dass Spring Boot alle für das Caching benötigten Spring Framework-Klassen bereitstellt, obwohl in der @SpringBootTest Annotation festgelegt wurde, dass nicht der komplette Spring IoC Contrainer gestartet wird.
Fazit
Caching ist ein mächtiges Tool, um die Performanz unserer Anwendung zu steigern. Das Spring Framework ermöglicht uns die Anwendung um einen Cache zu erweitern, ohne dass wir dabei die Applikationslogik anfassen müssen - aus meiner Sicht eine sehr praktische Lösung.
Den kompletten Source-Code zu diesem Artikel findet ihr in GitHub:



Kommentare